Why AI Forgets


Author’s Note:
Welcome! I’m Josh Wand, a senior engineer and product manager for almost 20 years. As a member of the Oregon Trail Generation, I often find myself explaining technology to a more general audience. Lately that’s meant explaining and contextualizing AI, so I decided to start sharing some of that here on this Substack (and on its companion wiki Base Models)
This particular article is foundational, and therefore a bit long, but understanding how text-based AI works will give you a framework for understanding AI’s power, as well as its limitations.
ChatGPT has a memory problem
If you’ve ever tried to have a conversation of any length with ChatGPT, Claude, or any other AI chatbot, you may have encountered a situation like this:
[…discussion about an essay the user is writing]
Assistant: Do you want your essay to discuss the impact of AI?
User: My professor insists we refer to AI as “A.I.” with the periods.
Assistant: Sure, from now on I will refer to AI as “A.I”.
User: Ok, let’s get back to work on my essay.
[…]
[a long back-and-forth about various parts of the essay]
[…]
Assistant: … and the question arises: is AI destined to destroy humanity?
User: Hey, I told you to refer to it as “A.I.”, with periods!
Assistant: I’m terribly sorry, you’re right! From now on, I’ll be sure to refer to Artificial Intelligence as “A.I.”, with periods.
The consequences of this can be significant—a friend told me about a long conversation trying to diagnose a health issue for his dog, and ChatGPT started suggesting that failed to take into account the dog’s complete health history. Fortunately, this friend was sharper-eyed than the AI and noticed the issue, but it could have ended very badly.
(Note to reader: please don’t blindly trust AI responses on anything! We haven’t even talked about hallucination yet.)
If you want to understand why this kind of thing happens, or really anything about why text-based AI behaves the way it does, read on.
All LLMs Do is Guess the Next Word, Over and Over
What follows is a extreme simplification of a complex and evolving science. Don't take it too literally. ¯\_(ツ)_/¯
Text-based AI is based on something called a Large Language Model (LLM). LLMs are essentially sequence generators—or, put another way, next-word1 guessers. They take a sequence of text (your prompt and whatever context you give it), and based on how often it’s seen that sequence in its training data, its job is to predict what the best next word will be:
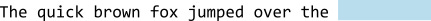
These models are “trained” on vast amounts of text—sequences of words. Billions of articles, webpages, books, code, documentation, blogs, and more. The training process works by taking a given sequence of text, and hiding the last word. The training program takes its best guess at what the hidden word is, based on all the other times it's seen something similar to the prior sequence:

It then judges how far off its guess was from the actual target word, and (hand wavey math 👋🧙♂️) adjusts the probability, either up or down, whether next time, given a similar sequence, it should or should not use the word it guessed.
Then it adds the guessed word to the sequence, slides forward, and does the whole thing again, including the new word:

Training a LLM from scratch means doing this calculation many trillions of times.
When a LLM responds to you, it evaluates all those probabilities for the input sequence, which includes the entire conversation thus far, including the current response being generated, and picking the most likely next word. Then, sticking that word at the end, it does the probability calculation again. And again. (This is why you get your responses in a stream, one word at a time.)
All of this in service of getting their next-word guesses as close as possible to what they’ve seen in their training data. A 100% accurate LLM, in theory, would exactly reproduce the most likely sequence from its training data. Since doing the exact probability calculation in real time with all 8 trillion tokens of training data isn’t physically possible, it uses some clever math to be able to takes its best guess on a much sparser version of the same data.
Why AI Forgets
Going back to training, however, when performing the "how good was our guess" adjustment, it doesn't give the same weight to all the words in the sequence:
It gives higher importance to the most recent words:

What that means, in practical terms, is that the longer your conversation, the less influence the earlier content has.
The Missing Middle
When an AI starts forgetting things from earlier in the conversation, there are two possible explanations.
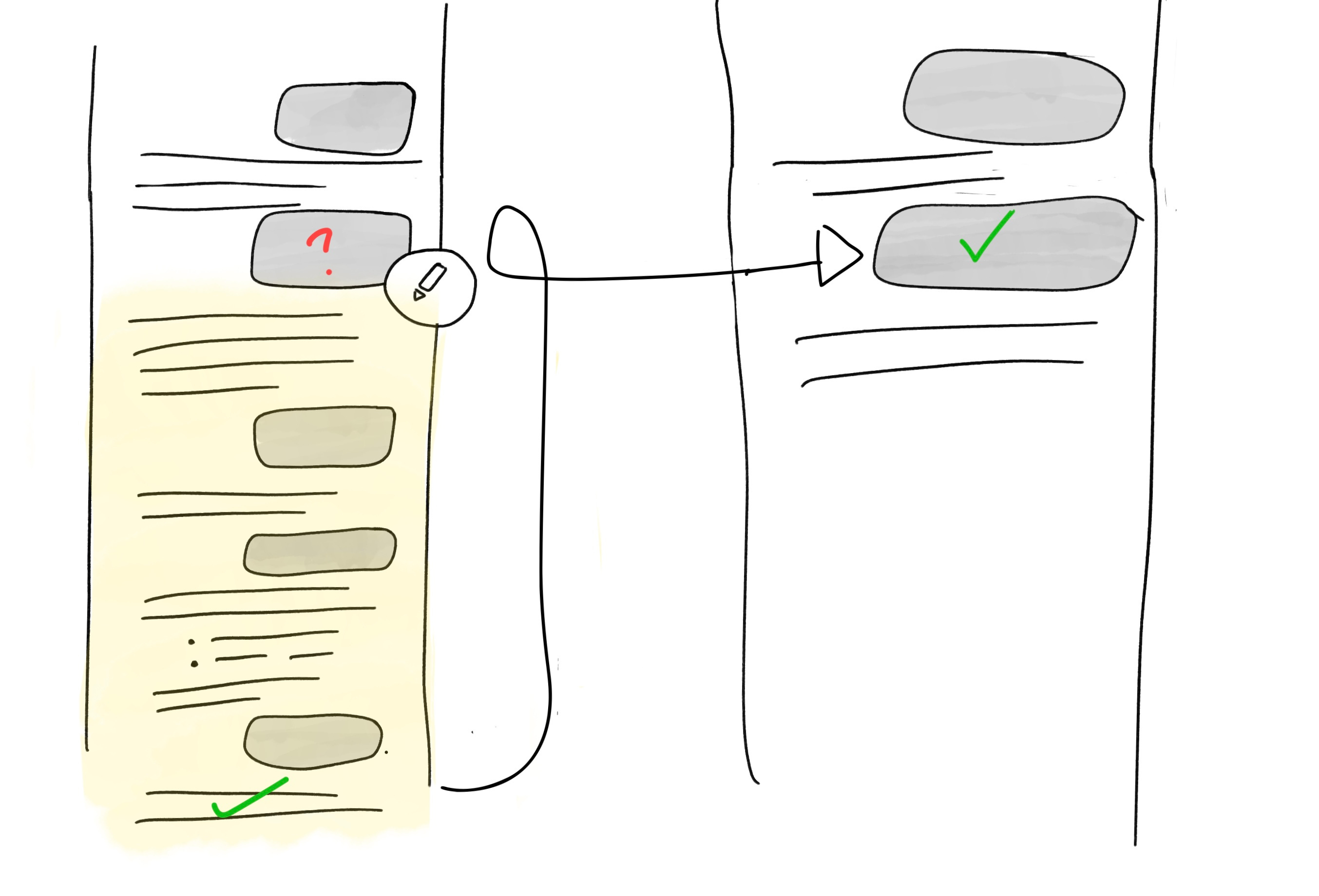
As discussed above, the LLM is focused on the only the most recent messages, and your instructions farther back have been de-emphasized. Most models add extra weight to the beginning of the conversations, to try to preserve your initial intent or instructions. What gets ignored is actually the middle of a long conversation:
Silent Summarization
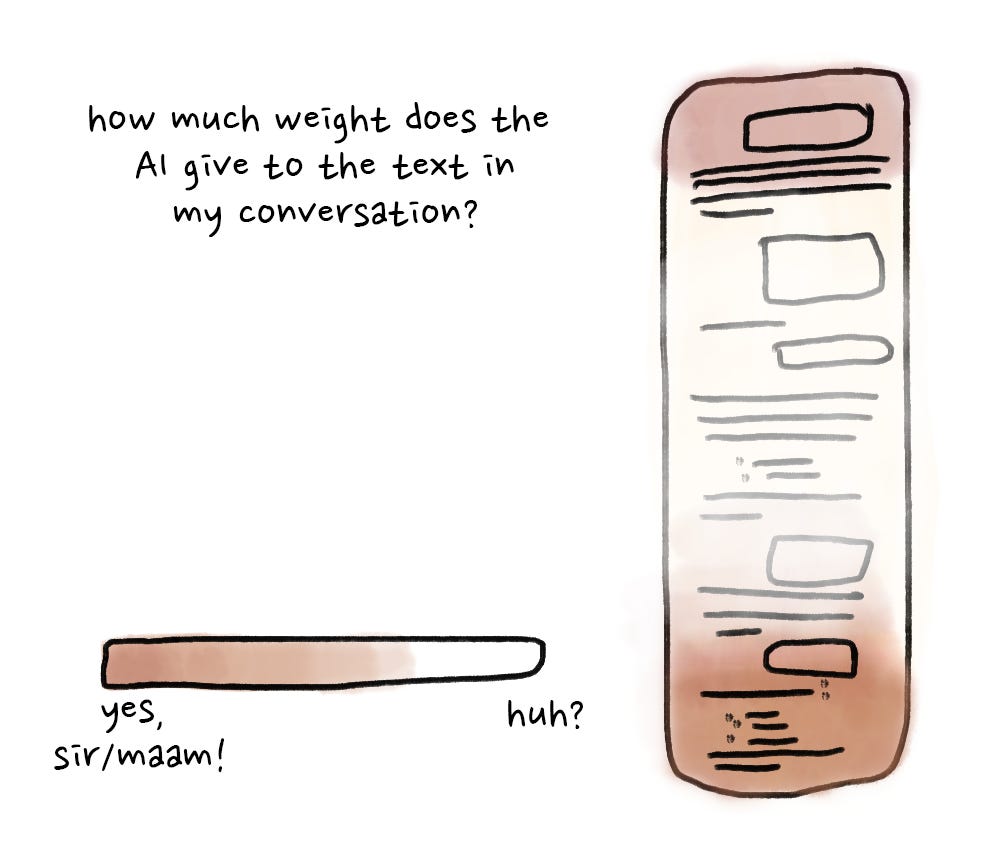
Or, your chat is now so long that it exceeds the available context length, and to fit into the window, the system has silently summarized the beginning of your conversation:
When LLMs are trained, they are trained with a certain "context length"—during training, this is analogous to the size of the sliding window being evaluated when guessing the next word. When you’re chatting, this represents the maximum amount of data that can be passed to the model for next-word-guessing. Large context lengths are more expensive to serve—the more data that needs to be evaluated, the more resources (compute, memory, power) are required for each next-word-guess.
To fit within the available context length, and to save money, AI providers will just shorten your conversation. An unsophisticated tool will happily cut off the beginning of your content, but most will make an attempt to summarize the early conversation. It will effectively take the first N% of your conversation, ask a different LLM to summarize it, and then use the summary instead of the actual content of your conversation.
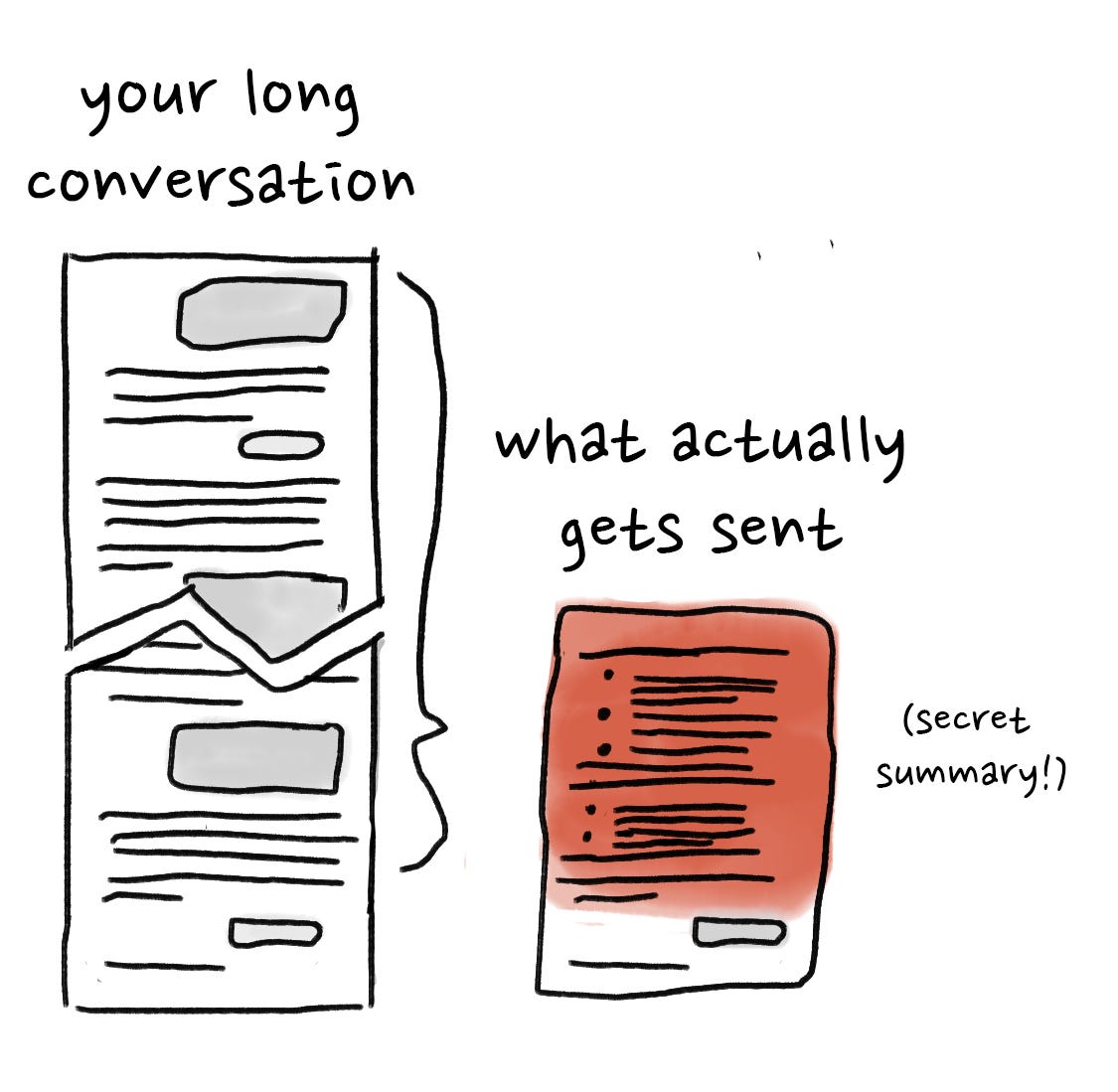
As with any abridged content, detail is lost in the process. Which details are lost? We don’t know, because the apps don't show us (or even tell us that they're not sending the whole conversation).
Hopefully those details weren't important to you. ¯\(ツ)/¯
More than just the detail, though, you've just lost control of the narrative.
How do I prevent LLMs from losing the plot?
Taking into account how LLMs and their interfaces work, here are a few concrete strategies to avoid the “forgetting” problem and keep the AI more consistent:
Keep conversations short and focused; handoff to a new conversation
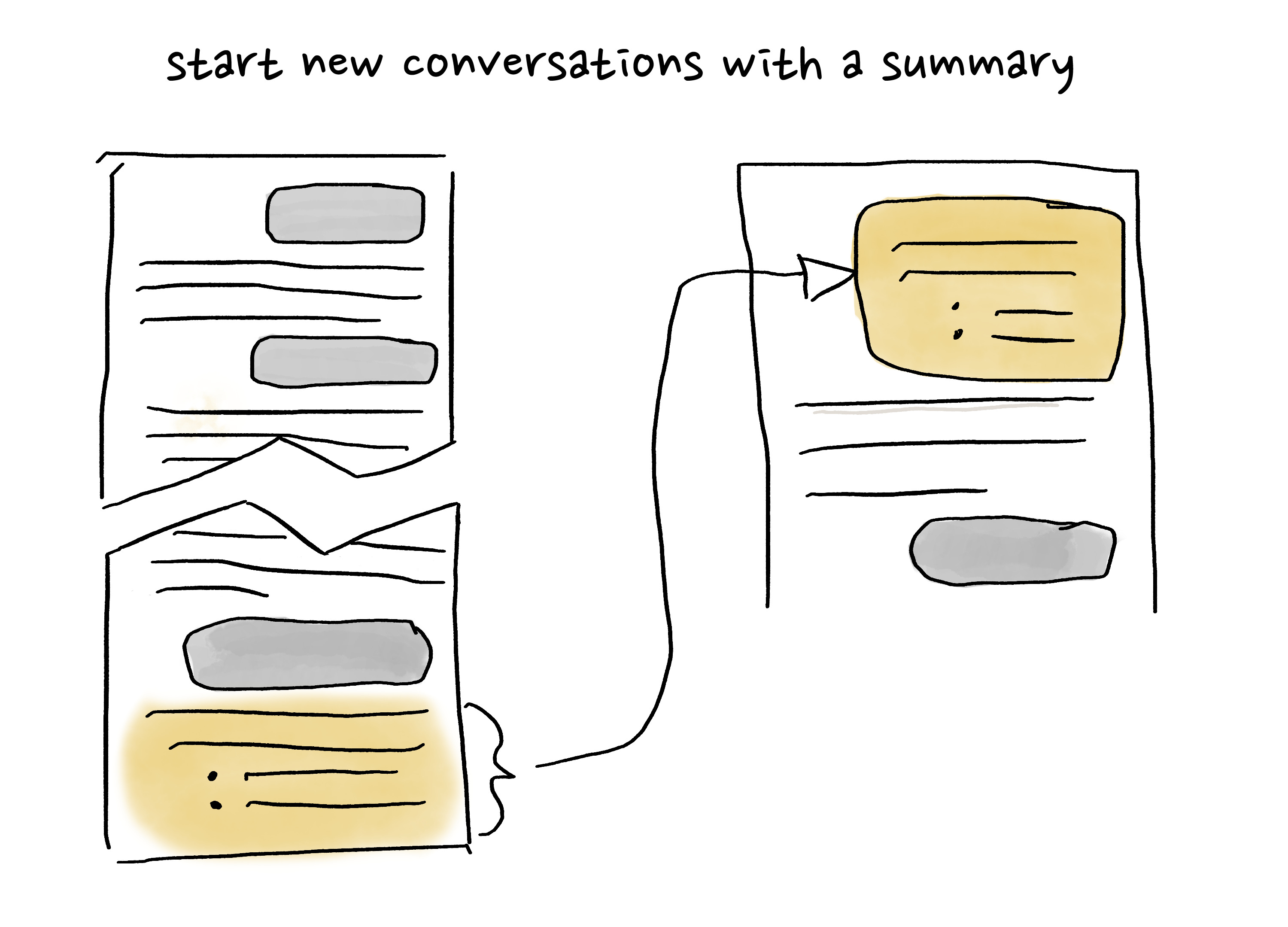
If your conversation starts to get too long, you run the risk of losing important stuff. When you’ve strayed further and further afield of your original task, or the conversation is just very very long, it’s time to start a new conversation.
You don’t have to start from scratch, though! Ask the AI for a summary of your conversation up til now (or your current working draft, working decisions, etc.), including all relevant facts and details, so that a new chatbot would be able to continue without any additional context. You can collaborate with the AI on the handoff document if you think it’s left something out or got something wrong.
For longer-term projects, consider PersistentContext.
Go back in time
I often end up on “side quests”—back-and-forths as I try to figure something out with the AI’s help, or how to phrase something in a way the AI “understands”. This risks distracting the AI with the details of the side conversation, rather than the main substance. Here’s a simple technique to prevent the AI from getting distracted: when you get a response that you don’t like, instead of having an extended dialogue to clarify it, go back end edit the previous message, adding clarifications or caveats. If the AI still makes a mistake, add that as an additional condition to your original message.
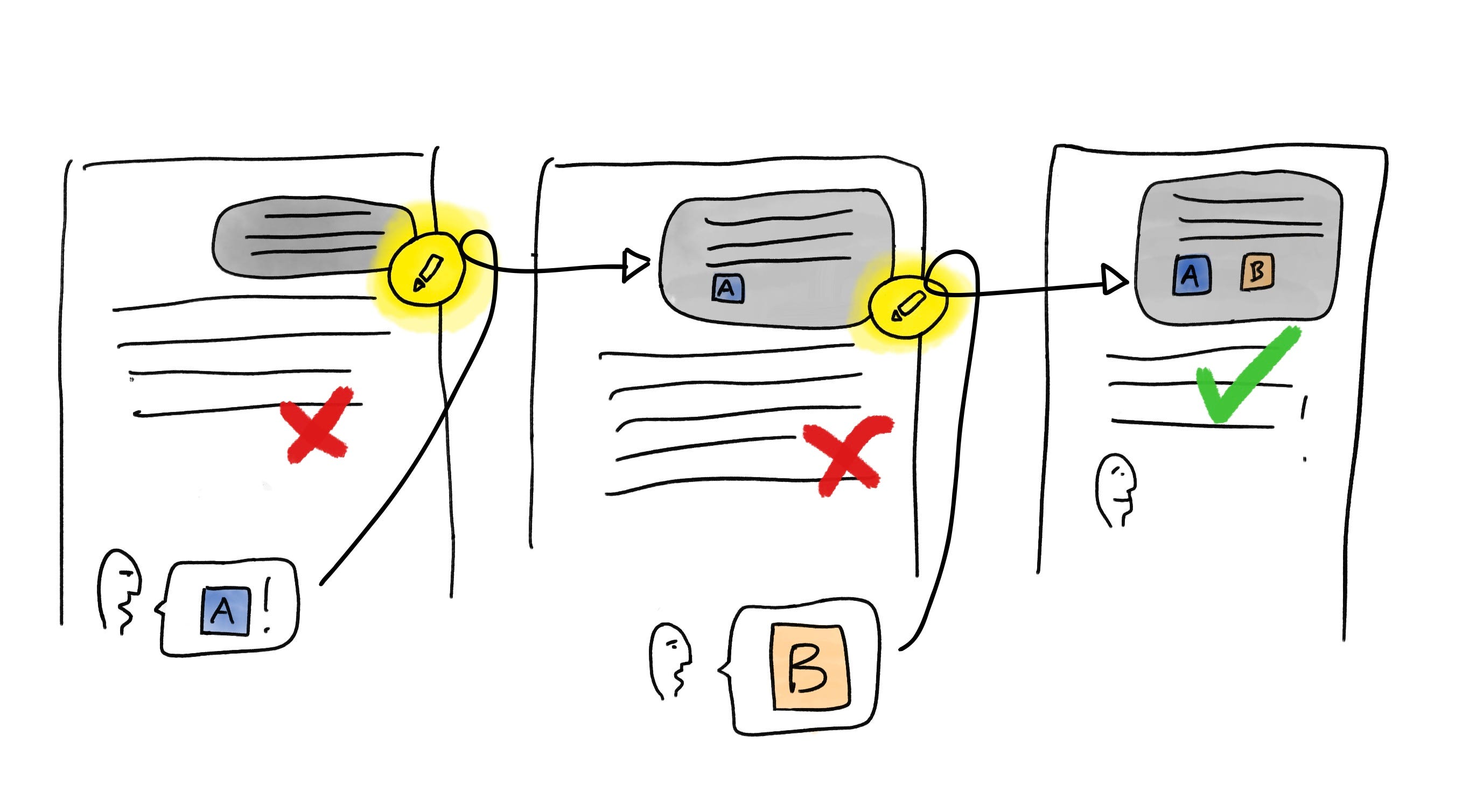
Alternately, if you do end up on a tangent that yields an interesting insight, scroll back to the point in the conversation where you wish you’d had that insight, and restart your conversation from there—edit the first side-tracking message to continue the conversation with your newfound knowledge.
Create a set of rules, and remind the AI periodically
If you have a set of constraints that the AI has to operate under, phrase them somewhere as a brief list. Periodically, include the list in your message:
Please rewrite the next section of my resume, keeping in mind:
• Each bullet point must fit on a single line
• Each bullet point must begin with an action verb
• Where possible, quantify the impact to the business
For coding assistants, I have a more advanced set of tools for maintaining requirements and instructions, which I’ll expand upon in a future post.
Advanced: Global Rules, with NamedPrinciples
Many tools like ChatGPT allow you to personalize your assistant by adding a set of instructions that get applied to every conversation2.
If you have certain conventions, rules, or standards that you always want your AI to follow, list them here.
These rules are still not perfect, and occasionally the AI will need to be reminded about a particular rule. To make this easier, I create a easy-to-type name for each rule, so I can just tell the AI exactly what rule it’s failed to follow.
Example:
## NoSyntheticData
**Definition**: If you encounter a problem when working with data, NEVER fall back to some fake or simplified data. You can do this in a test in order to debug the issue, but NEVER use fake data in non-test code.
[Examples of violations]
If I catch the AI oversimplifying the problem by using a contrived example, I can simply reply “NoSyntheticData” and it will know exactly what it did wrong and make the appropriate correction. (You can also combine this with the “Go Back in Time” technique, and simply append it as a reminder (“don’t forget: NoSyntheticData”) to your previous request that generated the bad behavior.
This works because LLMs have been optimized for “Needle-in-a-Haystack” use cases—retrieving relevant facts from earlier content. It might not proactively remember the rule on its own, but if you remind it, it can retrieve and re-state it to bring it to the front of its mind, so to speak.
Next: more misbehaviors and how to fix them
That’s it for AI “forgetting”. In future posts we’ll cover other kinds of misbehaviors, the reasons they happen, and how to use that knowledge to your advantage.
Thanks for reading!
Footnotes:
Technically not words but “tokens”, which are often just parts of a word.
In ChatGPT, these are in Settings > Personalize ChatGPT > “What traits should ChatGPT have?” and “Anything else ChatGPT should know about you?”